使用AVX2指令集加速Chrome浏览器的图像操作
指令集是CPU中用来计算和控制计算机系统的一套指令集合,也是软件与CPU硬件这两个层级之间的规范和接口:任何软件最终总要翻译成一条条指令才能让CPU硬件识别并执行,而CPU硬件则依靠指令来计算和控制系统。所以指令集功能的强弱和执行的效率是衡量CPU性能的重要指标,指令集的设计和使用自然就是提高CPU效率的重要环节。
正因为其无可替代的重要作用,每一款新型的CPU在设计时自然会精心挑选一系列与其硬件电路相配合的指令集。比如,英特尔1996年在其Pentium CPU架构设计中率先引入SIMD(Single Instruction Multiple Data,单指令多数据)指令集设计思想,添加了MMX(Multi Media eXtensions)多媒体扩展指令集,使其CPU能在一个时钟周期内用一条指令可以完成多个数据的操作,从而大大提高了CPU处理多媒体应用的效率。在一代代英特尔CPU架构的演进下,英特尔在2008年进一步公布了AVX指令集规范,并在Sandy Bridge CPU架构中将首先实现了全新的AVX指令集,把浮点矢量宽度从MMX时代的64位拓宽到了256位,最直接的收益就是浮点性能最大提升了4倍,并且在最新的AVX2中把整数的矢量宽度也同步增加到256位。
理论总可以描绘得很美好,但能不能应用到日常软件,为最终用户带来性能和体验的提升,这才是大家最为关注的。我们这里就举一个在我们实际工作中的例子,看AVX2是如何帮助大家常用的Chrome浏览器带来网页浏览上的性能提升。随着手机和电脑屏幕分辨率的不断提升,屏幕显示的分辨率往往会大于网页中图像的原始分辨率。此时Chrome浏览器就需要对图像进行放大。Chrome使用二维图形引擎Skia,运用Mitchell滤波器进行高质量的图像放大处理,而图像放大过程就是将图像与滤波器进行卷积操作(像素与滤波器系数相乘相加)的过程。由于图像一般表示为RGBA四个通道,每个通道存储0-255八位颜色值,因此最基本的方法是循环对每个像素的每个通道逐一运算(图1),但这样并不高效;而这样的操作其实很适合用AVX2指令集进行加速,因为AVX2可以一次处理256位数据,也就是8个像素,并且同时对RGBA四个通道进行运算(图2)。这样就可以大大提高运算效率,大幅获得速度提升。
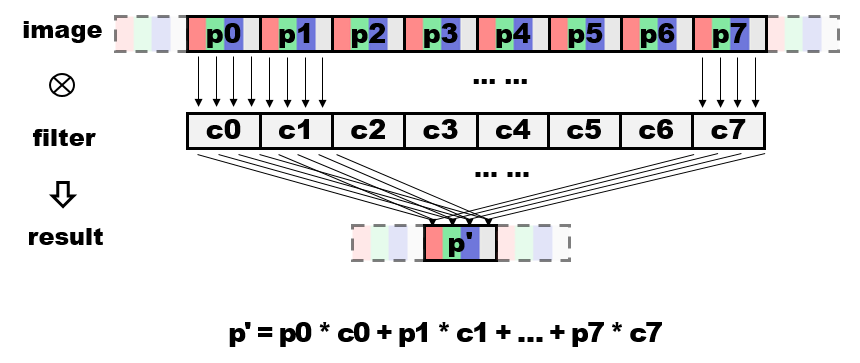
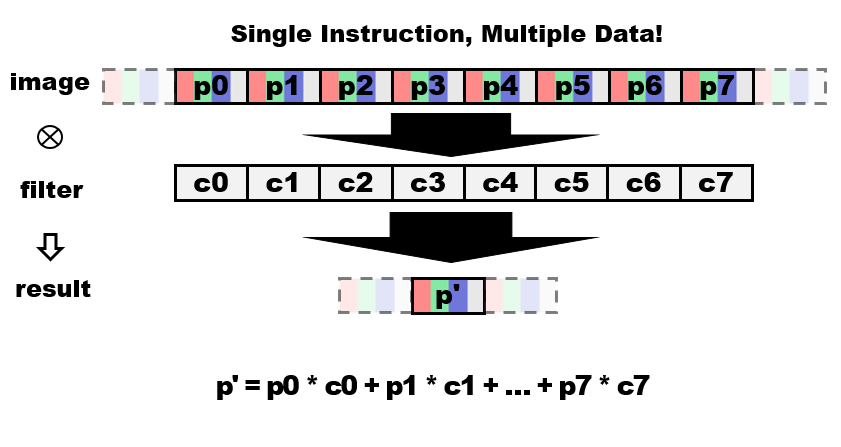
当然实际应用中需要考虑更多因素,而且整个二维图像滤波需要水平方向和垂直方向两次运算才能完成,因此算法的具体实现会比我们描述的稍微复杂一些。首先是位扩展和转换,我们一次读取8个像素也就是32个8位颜色值,但滤波器的系数是用16位的定点数表示的。我们需要先将8位颜色值扩展为16位,接着同时对16个16位整数进行乘法等操作,再把结果重新转换为8位颜色值存储并对溢出情况进行特殊处理。此外,还需对图像边缘(剩余不被8整除的像素)等情况进行特殊处理。但总的来说,我们的优化算法还是获得了可观的回报,在实际场景中,使用AVX2的算法相比原先SSE2的算法,可以达到近一倍的速度提升。