矩阵乘的CPU实现 - 简介
线性代数计算是计算机的一个重要应用领域,进行线性代数计算的程序库一般使用标准的BLAS接口。其中矩阵乘法计算在BLAS中叫做GEMM(general matrix multiplication)。计算公式为:
C = alpha*A*B + beta*C
其中A为M×K矩阵,B为K×N矩阵,C为M×N矩阵,alpha和beta为系数。
GEMM也是机器学习领域的一个核心运算。深度学习模型中的全连接层和卷积层都可以用GEMM实现。GEMM运算量很大,与M×K×N成正比,所以高效的GEMM实现是很重要的,一般都是硬件厂商专门养活一帮人来写针对硬件优化的库,如NVIDIA的cuBLAS。然后写框架的来调这些库,然后写包的来调框架,然后我们调包。
这里研究一下如何在CPU上进行GEMM计算。
现代多级缓存CPU架构上的GEMM计算算法,可以参考Goto等人的论文Anatomy of High-performance Matrix Multiplication。一个思想就是分块,把矩阵(M, Matrix)分为条(P, Panel),再把条分为块(B, block),将GEMM转化为GEBP。
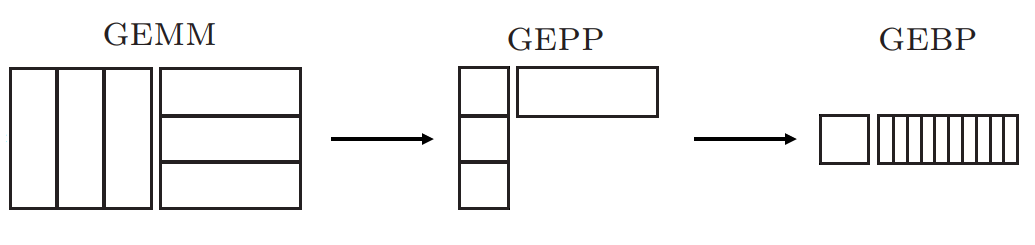
为什么要分块呢?是为了充分利用缓存,重用缓存中的数据进行计算。如果逐个计算的话,计算C矩阵的每一个元素都要读取A中的一行和B中的一列,计算下一个元素就要读取新的一行或者另一列,把原来放入缓存中的数据扔掉了,而读写内存操作的时间比计算操作要慢何止百倍。分块后就先把矩阵的一块读进来,用这些数据做更多的计算,提高计算操作与内存读写操作的比例。
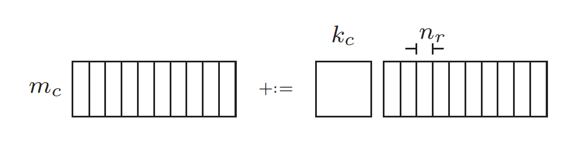
GEBP的计算依然需要分块。一个GEBP计算,C=A×B,A可以一直留在缓存中,B和C一块一块的进入缓存进行计算。
由于现代CPU有多级缓存体系,从寄存器到L1/L2/L3缓存到RAM,所以具体实现更为复杂,需要考虑分块放在哪一级的缓存。而除了缓存层级的分块(MC, KC, NC),还有寄存器层级的分块(MR, NR),这是最小的计算单元了。
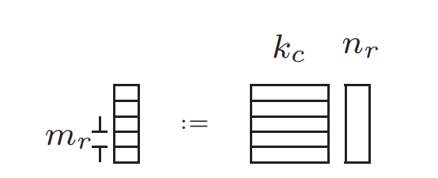
本文简单的介绍了一下矩阵乘的计算方法,理论上的具体细节可以直接看上面提到的论文。接下来看一看实际的工程代码中矩阵乘是怎么实现的。