矩阵乘的CPU实现 - Eigen
上篇文章简要介绍了矩阵乘,这篇我们来看Tensorflow CPU后端所使用的C++ header only线性代数计算库Eigen是怎么进行GEMM计算的。
计算流程
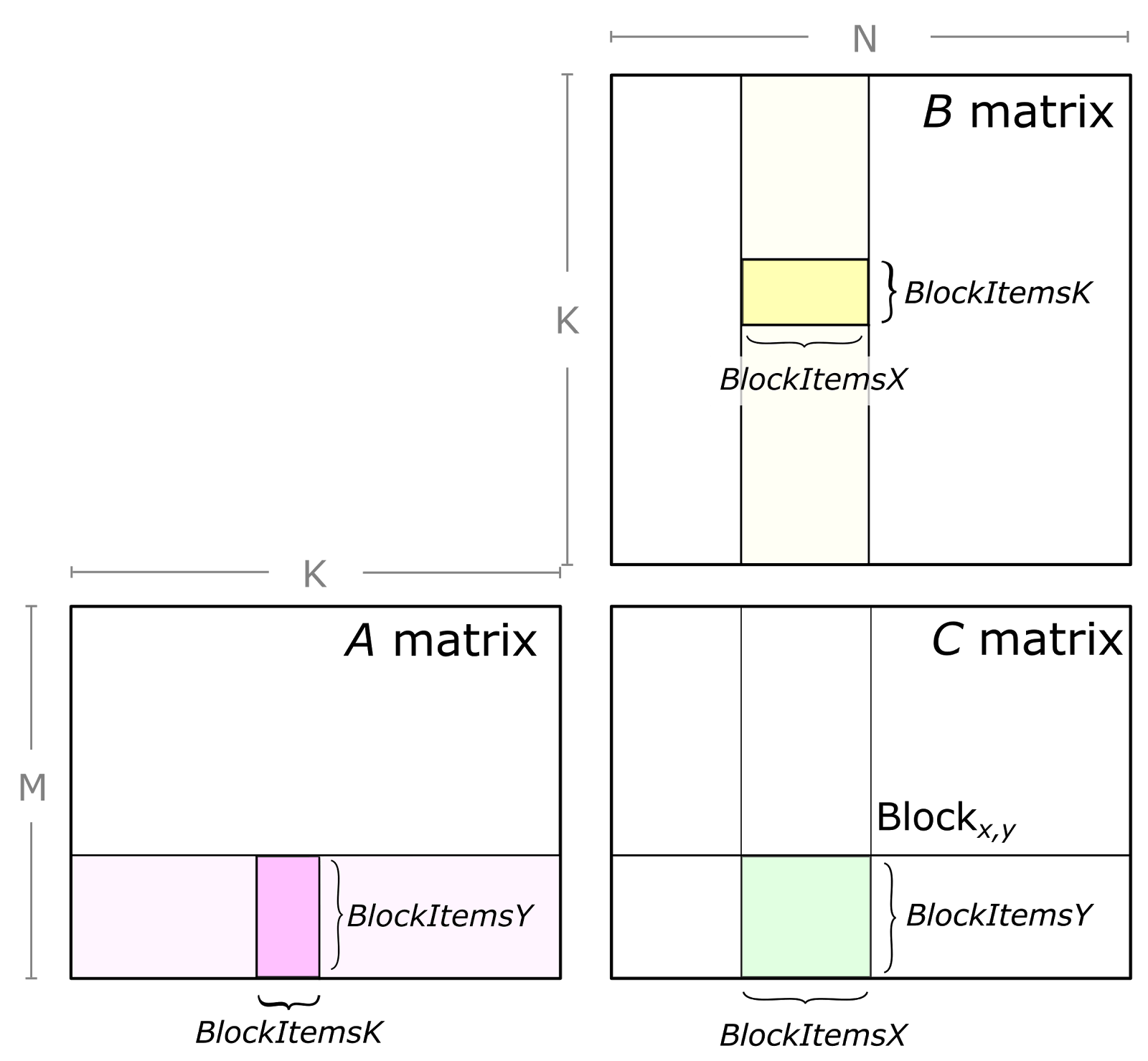
Eigen中GEMM计算的高层逻辑在GeneralMatrixMatrix.h文件,主要分为三步。
- 第一步是分块,由
gemm_blocking_space类实现。分块的结果就是得到MC KC NC的值; - 第二步是打包(pack),把每份分出来的小矩阵块放入一个连续内存中,方便下一步计算;
- 第三步是块之间的矩阵乘计算。C中的每个大小为
MC×NC的块都由K/KC个A的小块和K/KC个B的小块的矩阵乘结果求和得到,块之间的矩阵乘用GEBP实现。
计算过程就是三重循环算每个小块了:
for i in 0 to M/MC:
for k in 0 to K/KC:
pack blockA(i,k)
for j in 0 to N/NC:
pack blockB(k,j)
blockC(i,j) += gebp(blockA(i,k), blockB(k,j))
而分块,打包和GEBP的具体实现均在GeneralBlockPanelKernel.h文件。Eigen也可以把general_matrix_matrix_product类偏特化了,调用其他BLAS库如MKL来进行GEMM。
多线程下的GEMM
上面讨论的是单线程的情况。为了提高效率,我们需要利用多个CPU核心进行计算。所以首先要把GEMM任务分解给多个线程进行计算。这块的逻辑在parallelize_gemm函数中,使用了OpenMP进行多线程,按N的维度分解,把结果C纵向按列分为多块,每个线程计算C中的一块。
按列分块是因为Eigen默认结果C是按列存储的(Column Major),计算按行存储(Row Major)的结果也是通过计算CT=BT×AT,按列存储来算的,因为按行存储的C等于按列存储的CT。(而A, B的存储方式是无所谓的, 打包的过程会把AB转换为按块存储的格式)。
多线程下的计算逻辑如下,每个线程计算自己的C':
for k in 0 to K/KC:
pack blockA(0,k) // multi threaded
for j in 0 to N/NC:
pack blockB(k,j)
blockC(0, j) += gebp(blockA(0, k), blockB(k, j))
与单线程计算的一个区别是M维度不分块,省掉了一个循环,只有两重循环。A只分为K/KC列。
每个线程算不同的C中的一块C',B是不同的,但A其实各个线程是相同的,所以,我们可以所有线程共享一个blockA,同时多线程的pack blockA,将blockA横向切分为多块,每个线程pack一块。blockB每个线程是不同的,所以需要各自pack。
具体实现中,循环中更新blockA后的第一个GEBP计算会特殊处理,也分为多块。每个blockA当前线程pack的部分在pack完成后就直接拿这一小块做GEBP。
分块
不同数据类型不同CPU架构会有不太一样的逻辑,这里只挑一个路径来看。下面看的是float类型的GEMM,在x64架构AVX指令集下的计算路径。
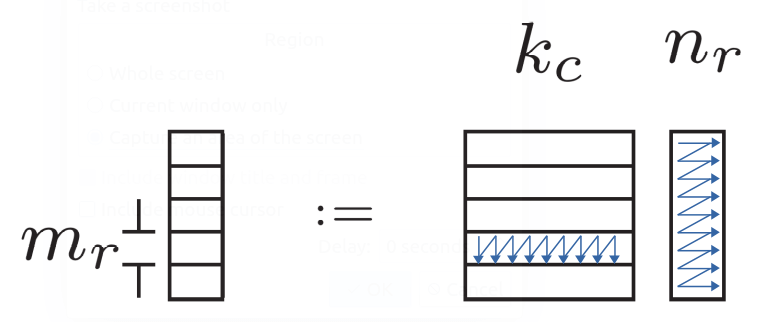
确定MR NR
首先确定的是MR和NR的值,这两个值决定的是最里层寄存器层面的计算块Cmr×nr=Amr×kc*Bkc×nr的大小。
理论上是一半的寄存器分给结果Cmr×nr,一半的寄存器分给A和B。实际上Eigen中MR和NR两个值是常量,就写死的NR=4,分给Cmr×nr12个寄存器。AVX共有16个寄存器,一个寄存器256位放8个float。所以MR=12*8/NR=24。AVX向量化就是并行A的行的方向,AVX一次处理8行,所以MR就会比较大。
确定MC KC NC
由M K N计算MC KC NC,由函数evaluateProductBlockingSizesHeuristic实现。这里我最多能看懂它在干什么,但很难看懂为什么。“heuristic”嘛,越看越迷茫。就列一些看的懂的点吧。
- 如果MKN太小的话,就不用进行分块。
-
首先确定KC。理论是Amr×kc和Bkc×nr能放进L1中,另外KC需要是8的倍数(为了循环展开)。另外在K维度分的块也得均匀。所以会调整KC,不要最后剩余一个很小的块。
例如使用8核的i9-9900K CPU,L1D=32K, L2=256K, L3=16384K。计算M=1000, K=1000, N=1000的GEMM。 满足
max_kc * mr + max_kc * nr < 32K且kc是8的倍数得max_kc=288。所以k=1000最少分四块,均匀的分kc=256,k=256+256+256+232。 -
然后确定NC。理论是把L2的一半分给Bkc×nc。实际代码中L2的值用的是1.5MiB常量,令人迷惑。此外NC需为NR的倍数,且不能过大,要均匀。
还是上面的例子,
max_nc = 0.75MB / kc = 768。所以n=1000可分为两块,nc=500。 - 还有一种特殊情况,
kc=k没有分块时,如果L1还有空间容纳Bkc×nc,就把Bkc×nc放进L1。 - 最后是MC。默认M是不分的
mc=m。除非K和N都没分M才分。
多线程下有另外的一套计算方法。
-
T个线程下,首先N会均匀切成T块,且N应为NR的倍数。
还是上面的例子,8核CPU用8个线程
t=8,得每个线程的n=124。 -
然后算KC,这里又不均匀分了,迷惑。而且还限制了
max_kc=320。还是上面的例子,,可得
kc=288。 -
然后是NC,
nc=(L2-L1)/(nr*kc)。还是上面的例子,得到
nc=48。 -
最后是MC,Amc×kc需要能放在L3中,且最大为
m/thread_num。但实际上MC的值并没有使用,相当于
mc=m,不分块。
总之,分块的逻辑用了很多经验值,令人迷惑,没有太搞懂。
打包
打包(Packing)是为了将一个块内原来不连续的内存放在同一块内存区域中,方便后续的计算。具体的格式是和GEBP的计算相关的,以便进行最内层的Cmr×nr=Amr×kc*Bkc×nr计算。
所以BlockA的pack格式就是以MR为单位的一行一行进行pack,BlockB的pack格式就是NR为单位的一列一列进行pack了。
关于打包后块的内存的位置,单线程情况下,直接栈上分配。多线程情况下,A是公用的,所以堆上分配,B各用各的,所以栈上分配。
GEBP计算
GEBP是以固定的mr=3*packet size, nr=4为单位计算的。Packet是不同CPU架构下SIMD一次可以处理的数据量的大小。CPU不同,packet size不同。如AVX一次可以计算8个float, packet size就是8。
GEBP分解为Cmr×nr=Amr×kc*Bkc×nr计算。
每个这样的计算又是以K为循环进行计算,这个循环以8为单位循环展开(可以认为KR=8)。
最终分解为最小的计算单元Cmr×nr=Amr×kr*Bkr×nr。这个计算就没有任何循环了,所有计算大小都是固定的,直接用madd指令在寄存器里算就完了,AVX下就是用_mm256_fmadd_pd指令,计算的结果累加到寄存器里。Cmr×nr算完后再写入内存中blockC的相应位置。
剩余的不能以mr×nr为单位进行计算的部分会特殊处理,可能就不能完全用AVX指令来做了。
Eigen-unsupported Tensor实现
Eigen除了本体之外,还提供了一套Tensor库,Tensorflow其实用的是这一个库。Eigen Tensor可通过Tensor contraction接口来进行GEMM操作,具体实现在TensorContraction.h文件,和Eigen本体不一样。但分块,打包,GEBP都是用的Eigen本体内的函数。
计算过程依然是三重循环算每个小块:
for i in 0 to M/MC:
for k in 0 to K/KC:
pack blockA(i,k)
for j in 0 to N/NC:
pack blockB(k,j)
blockC(i,j) += gebp(blockA(i,k), blockB(k,j))
output_kernel(blockC)
逻辑几乎和前面一样,但输出时可以加一步后处理计算,可直接融合进去ReLU等操作。
多线程
Tensor的计算包含有多个后端实现,除了默认的单线程CPU,还有ThreadPool, CUDA等。选择ThreadPool线程池可以进行多线程计算。具体实现在TensorContractionThreadPool.h文件。这里还有同步和异步两种模式。为了方便起见,下面只关注同步模式。
- 实现原理:把packA,packB和GEBP计算看作一系列有依赖关系的任务,分配到线程池中进行执行。
- 总的任务数量为:(M/MC)*(K/KC)个packA, (K/KC)*(N/NC)个packB, (M/MC)*(K/KC)*(N/NC)个GEBP。
- 依赖关系为:GEBP(i, k, j)按k的顺序依次进行,依赖于GEBP(i, k-1, j),packA(i, k)和PackB(k, j)三个任务完成。
- 限制并行程度:并行的k只有两个。
- 具体实现:非常复杂,非常多的参数,实在是看不下去了。
参数
这里的多线程实现很复杂,需要确定的参数也很多。
Eigen中的多线程是把结果C纵向按列分为多块,每个线程计算C中的一块。这里不一定了,先确定按列分还是按行分块还是按K来划分计算。当然默认还是按列分,除非更适合按行分或者K分(如当K或者M特别大的时候)。按行分的话,实际上是计算BT×AT,依然转换为按列分的情况。
还有一个需要确定的是用几个线程来进行计算,这个值也是可以变的,由TensorCostModel来确定。GEMM计算需要的周期包括计算和内存读写,可以根据MKN的值估算。假定开一个线程的开销需要10万个周期,总计算量为x个周期的GEMM计算最多开几个线程合适呢?根据TensorCostModel就能算出来一个值来。
然后计算MC KC NC,依然是用的evaluateProductBlockingSizesHeuristic函数。这里和上面的区别就是M又分块了。然后计算怎么分task,一个task可以处理多少块。然后计算是否并行的pack。
所有这些参数都确定了,才开始进行并行的计算过程。
总结
本文介绍了Eigen中矩阵乘计算的CPU实现,接下来会看一看Tensorflow中矩阵乘是怎么实现的,因为Tensorflow基于Eigen又进行了一些改动,加入了自己的实现。